


Source code can be a fantastic source of knowledge. Not only can natural language be mapped to source code (to a programming language, actually), but to analyze and process programs in the past, we have dozens of representations for each programming language.
An Abstract Syntax Tree (AST) is the hierarchical representation of code tokens of a given program. Abstract because whitespace and format style is no longer critical. A Control Flow Graph (CFG) can depict what elements are in charge to execute a specific conditional branch of function. A Program Dependency Graph (PDG) can show what code parts or functions are required for a particular computation. A well-known layered presentation format for them is Code Property Graphs (CPG)[1], introduced by Yamaguchi. Take a look a joern.io if you want to play with it.
No matter what representation you chose, sooner or later, you want to work with your tree/graph by traversing through it, or maybe you need to detect whole patterns. This is where PSITrees gets interesting, which are a variant of ASTs.
PSI is an acronym for Program Structure Interface, responsible for parsing source code and building syntax trees. It is used in the IntelliJ Plattform to create representations of code. The platform includes many IDEs of Jetbrains like IntelliJ IDEA, PyCharm, and CLion. A PSI element can be a file or a word of a program. Because the combined elements are hierarchical aligned, a set of PSI elements is also called PSI tree. Also, those trees are Concrete Syntrax Trees (CST); they include all comments and whitespace of the original program[2].
Kurbatova et al. give a small example in their paper. Let's take this snippet:
char getChar(int a) {
return (char)a;
}The PSITree of this function would look like this:
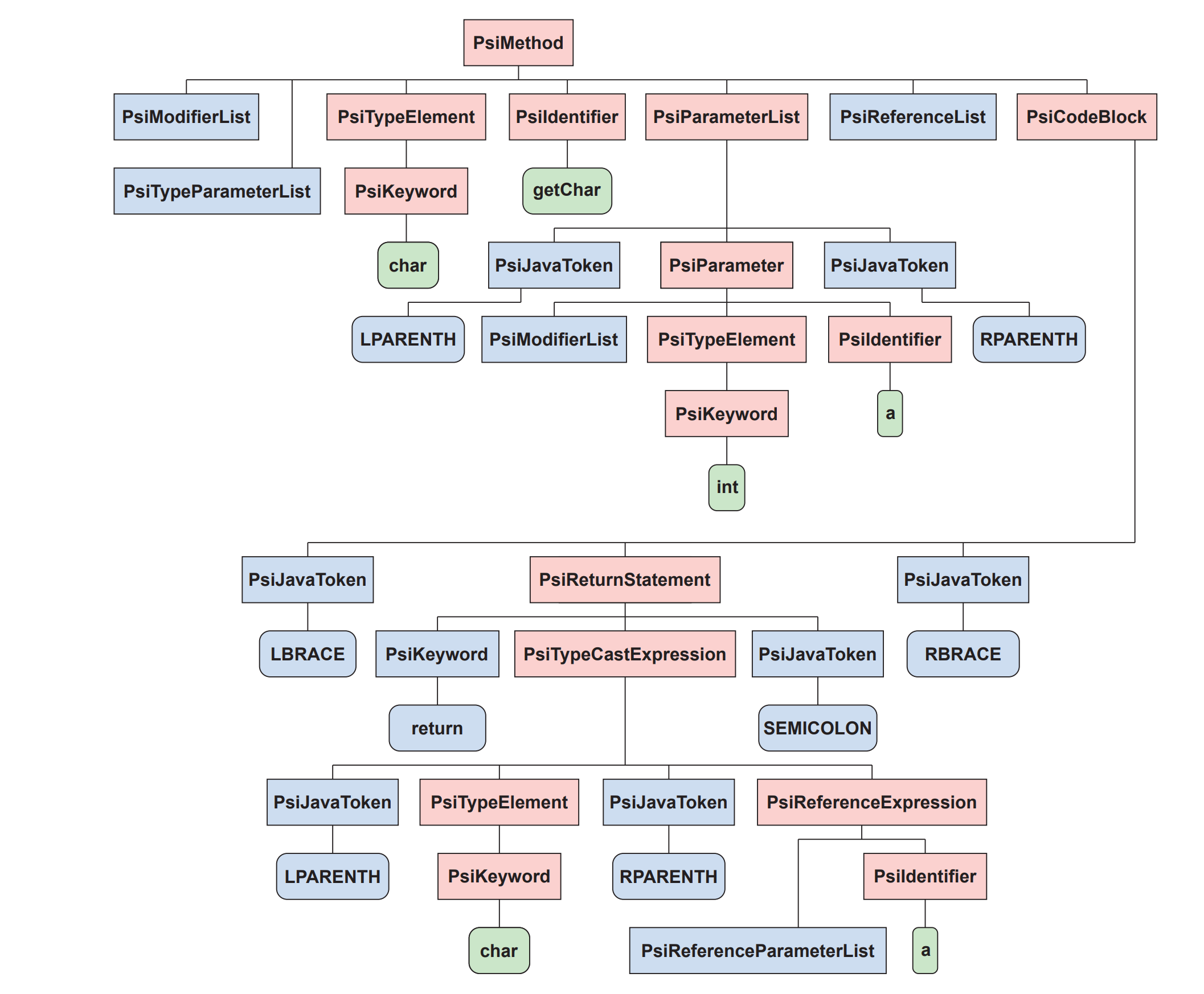
PsiWhiteSpace nodes are omitted for readability [2]Apart from all the possibilities given by the IntelliJ platform, the mining aspect seems to be the most interesting. PsiMiner is a tool that collects PSI trees from several projects or even single files, extracts the AST, applies labels for other machine learning processes, and saves the samples on disk. It is possible to ignore nodes and filter AST parts by a configuration file. The project is available on Github[3].
Unfortunately, PsiMiner supports only Java and Kotlin at the moment. It would be very nice to have the same for Python, C, and JavaScript/TypeScript.
References
- Yamaguchi, Fabian, Nico Golde, Daniel Arp, and Konrad Rieck. 2014. "Modeling and Discovering Vulnerabilities with Code Property Graphs." In 2014 IEEE Symposium on Security and Privacy, 590–604. https://doi.org/10.1109/SP.2014.44.
- Kurbatova, Zarina, Yaroslav Golubev, Vladimir Kovalenko, and Timofey Bryksin. 2021. "The IntelliJ Platform: A Framework for Building Plugins and Mining Software Data." arXiv [cs.SE]. arXiv. http://arxiv.org/abs/2110.00141.
- Spirin, Egor, Egor Bogomolov, Vladimir Kovalenko, and Timofey Bryksin. 2021. "PSIMiner: A Tool for Mining Rich Abstract Syntax Trees from Code." In. http://arxiv.org/abs/2103.12778.